おもしろ訳をkindleにいれる(EPUB作成,Pythonスクレイピング)
- 電子書籍のフォーマット(適当)
- kindleでEPUBが使えるようになる
- EPUBフォーマット
- EPUBファイルを入手する
- EPUBをZIPで展開,圧縮
- vscodeでEPUBを読む 拡張機能
- kindleにEPUBファイルを送る
- markdown, xhtml+cssどちらで書くか
- EPUBを書く
- Pythonスクレイピング
- 複数のページを一つxhtmlファイルに書き込み
- コード全体
- 不要な要素を正規表現で削除
- css
- 完成
こちらのサイトの徒然草の訳が大変おもしろく,現代にあっているため,Kindleで読みたい.
「もし灰になった死体の煙のように命が永遠に漂っていたとすれば、もうそれは人間ではない」
— ㋙゚㋑゚㋟゚㋮゚ (@Koituhatama) 2022年11月11日
「没落する夕日の如く、すぐに死ぬ境遇」
「『死ぬことの楽しさ』が理解できない、ただの肉の塊でしかない。」https://t.co/dwLv1PfKlZ pic.twitter.com/9Y10MFFJqs
Kindleにはマーカーを引くことによって,いつでも読み返したいところを読み返すことができる大変便利な機能が存在する.
この記事では
を行う.
電子書籍のフォーマット(適当)
リフロー型
文字の大きさなどが変わる
フィックス型
文字の大きさなどが固定
kindleでEPUBが使えるようになる
電子書籍にはMOBIとEPUBなどのフォーマットがあり,KindleではMOBIに変換しなければいけないらしかったが,2022年5月にEPUBを対応したらしく,読み込めるようになっている. MOBI形式について調べたが,人間には読み書きできるものではなく,コンピュータが処理する用のデータであった.また,2022年後半からは一部の手段で送信できなくなるので,できるだけ使用を控えたい.
EPUBフォーマット
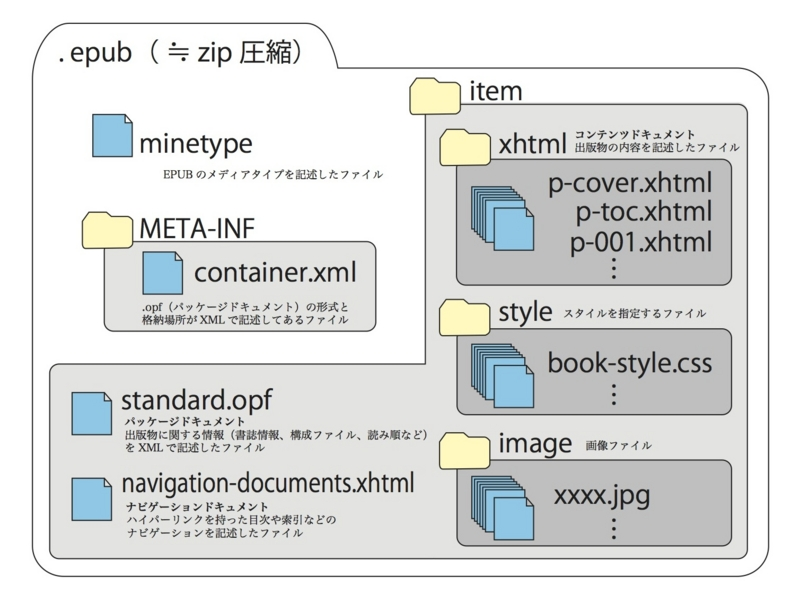
電子書籍づくり実践(EPUBの構造 xhtmlとcss) - 本好きに送る「電子書籍のつくり方」講座
EPUBファイルを入手する
Push to Kindleというchrome拡張を使用して,サイトの1ページのみをEPUB形式に変換.

EPUBをZIPで展開,圧縮
EPUBは拡張子を.epubから.zipに変換して展開することで中身を展開して,見ることができるらしい.おもしろだ!
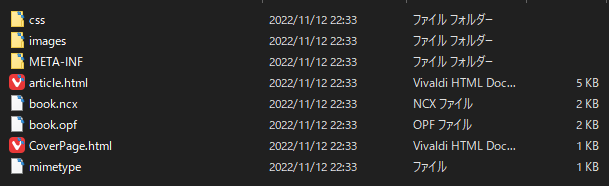
また,展開したファイルをzipで圧縮して.epubに拡張子を変えることでkindleなどで読み込めるらしい.
やってみたが,できなかった.
どうやらzip圧縮のコツがあるらしい.
$ cd ディレクトリebookへのディレクトリパス $ zip -0 -X ../ebook.epub mimetype $ zip -r ../ebook.epub * -x mimetype $ cd ..
Windows 8.1の場合は、 まず、mimetypeファイルだけを右クリックして「送る」を選び「圧縮(zip形式)フォルダー」を選ぶと、mimetype.zipが出来ます。 次に、mimetype以外のファイルを全てmimetype.zipにドラッグ アンド ドロップして追加します。 最後に、mimetype.zipを例えば○○.epubへファイル名を変えます。
第4話 電子書籍(ePub)の展開と再圧縮 - 電子書籍を作成しよう!(エリファス1810) - カクヨム
上記の方法を行うことで,読み込めるEPUB形式のファイルを生成することができた.
zip -0 -X export_book\turezure_150_4.epub mimetype zip -r export_book\turezure_150_4.epub * -x mimetype "./export_book/*"
最終的にこのようなコマンドになった
export_bookというディレクトリ以外をzip化する
windows環境ではzip.exeをインストールする
windowsでzipコマンドを使うためにはzip.exeをインストールしなければならない. 筆者のデスクトップ環境ではLiveTexをインストールしたときに一緒にインストールされていて気が付かなかった.
Windows上でzipコマンドを使用する為の方法 | そう備忘録
上の記事を参考にしてインストールを行った.
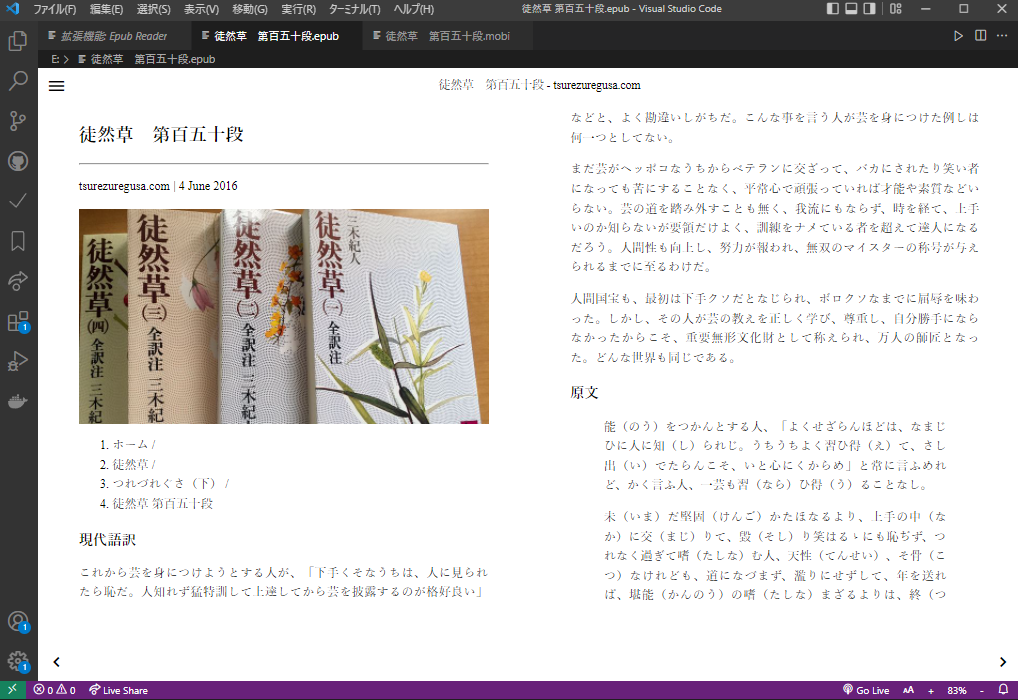
vscodeでEPUBを読む 拡張機能
kindleにEPUBファイルを送る
送るには
がある.
ローカルな端末内に保存する方法ではなく,amazonのサーバー内に保存するパーソナルドキュメントにできれば,ラインマーカーを共有することができるはず
send to kindle(iPhoneの「kindleに送信を使う」)を使用して,送信してみた.

軽く見たところ,
- Kindleで小説を読むみたいに縦書きが良い
- いらない情報があるので編集したい(画像では見えないが,人気のページリンクや画像)
などの不満がでてきた.
また,全ページを取得し,一つのEPUB形式のファイルにしてkindleで読みたい
markdown, xhtml+cssどちらで書くか
編集するにあたって,
の方法がある.
とりあえず,xhtml+cssでEPUBファイルを生成していくように進めていく.
なぜならmarkdownの変換先がEPUBファイルであり,EPUBファイル自体を編集できると便利そうなので.
EPUBを書く
参考になりそうなガイドPDF
電書協 EPUB 3 制作ガイド | デジタル出版者連盟(旧・日本電子書籍出版社協会)
上の記事では,網羅的に内容が書かれているが,読むのが大変である.
自力でいちからEPUB形式の電子書籍を作ってみる! HTML/CSSの知識があれば十分!?|『人文×社会』の中の人|note
上の記事の基本が詰まっている記事 簡単にチュートリアルできるので大変オススメ
本記事では上のnoteをベースにEPUBファイルを作成する
ibookで読むかkindleで読むか
結果を書くとkindleでデバッグを行い,kindleで読むことになった.
本がユニークな扱いか
EPUBファイルは,.opfファイルの「dc:identifier」が同じだとiPadアプリのibookでは同じ本として扱われるためデバッグしにくい,そのため変更すると良い(kindleだと別の本として扱われる)
縦書き表示への対応
.opfファイルに
<spine page-progression-direction="rtl"> </spine>
「page-progression-direction="rtl"」をつけることで縦書き表示をすることができる.
.cssファイルには vscodeの拡張機能で確認したら効果があったスタイルを書く (kindle版に効果があるのかわからないが)
html {
-webkit-writing-mode: vertical-rl;
-webkit-text-orientation: mixed;
-epub-writing-mode: vertical-rl;
-epub-text-orientation: mixed;
writing-mode: vertical-rl;
text-orientation: mixed;
}
を記載しておく.
少し調べると,どうやら「.azk」という拡張子にファイル変換するといけるらしい...?
とりあえず,iPad用の縦書き対応は後回し(スマホで読めれば十分)
Pythonスクレイピング
スクレイピングによってWEBからページ内情報を自動取得する.
自動で各ページから
- タイトル
- 現代語訳
- 原文
- 注釈
を取得します
import requests from soupsieve import select from lxml import html from bs4 import BeautifulSoup import time r = requests.get(url) soup = BeautifulSoup(r.content, 'lxml') title = soup.select('header>h1')[0].getText() modern_translation = soup.select('article > section > p:nth-child(2)')[0].getText() original_text = soup.select('section > blockquote > p')[0].getText() annotation_text = soup.select('section > h4 ~ p') #section > h4 の兄弟のpタグから最後のpタグまで # print(f'現代語訳 {modern_translation}') # print(f'原文 {original_text}') # print(f'注釈 {annotation_text}') annotation_text_list = [] for v in range(len(annotation_text)): content = annotation_text[v].get_text().replace('\u3000','') if len(content) == 0: None else: annotation_text_list.append(content)
複数のページを一つxhtmlファイルに書き込み
# 初期要素の書き込み path = 'NOT_export/pywrite_test.xhtml' with open(path,'w',encoding='utf-8') as f: #w = 上書き a=追加 first_lines = [ '<?xml version="1.0" encoding="UTF-8"?>\n' '<!DOCTYPE html>\n' '<html\n' '\txmlns="http://www.w3.org/1999/xhtml"\n' '\txmlns:epub="http://www.idpf.org/2007/ops"\n' '\txml:lang="ja"\n' '>\n' '\n' '<head>\n' '\t<meta charset="UTF-8"/>\n' '\t<title>徒然草本文</title>\n' '\t<link rel="stylesheet" type="text/css" href="../style/style.css"/>\n' '</head>\n' '\n' '<body>\n' ] f.writelines(first_lines) def two_return_to_one_return(content:str): #改行コードを減らす content = content.replace('\n\n','\n') return content #真ん中 path = 'NOT_export/pywrite_test.xhtml' with open(path,'a', encoding='utf-8') as f: #w = 上書き a=追加 f.write('\n') f.write('\t<h1>'+title+'</h1>\n') f.write('\t<h2>現代語訳</h2>\n') f.write('\t<p style="white-space:pre-line">'+two_return_to_one_return(modern_translation)+'\n\t</p>\n') f.write('\t<h2>原文</h2>\n') f.write('\t<p style="white-space:pre-line">'+two_return_to_one_return(original_text)+'\n\t</p>\n') f.write('\t<h2>注釈</h2>\n') for v in range(0,len(annotation_text_list),2): #2づつ f.write(f'\t<h4>{annotation_text_list[v]}・・・{annotation_text_list[v+1]}</h4>\n') #最後 path = 'NOT_export/pywrite_test.xhtml' with open(path,'a', encoding='utf-8') as f: #w = 上書き a=追加 # # end f.write('</body>\n') f.write('</html>')
コード全体
import requests from soupsieve import select from lxml import html from bs4 import BeautifulSoup import time def get_text_and_write_file(url:str): r = requests.get(url) soup = BeautifulSoup(r.content, 'lxml') title = soup.select('header>h1')[0].getText() modern_translation = soup.select('article > section > p:nth-child(2)')[0].getText() original_text = soup.select('section > blockquote > p')[0].getText() annotation_text = soup.select('section > h4 ~ p') #section > h4 の兄弟のpタグから最後のpタグまで # print(f'現代語訳 {modern_translation}') # print(f'原文 {original_text}') # print(f'注釈 {annotation_text}') annotation_text_list = [] for v in range(len(annotation_text)): content = annotation_text[v].get_text().replace('\u3000','') if len(content) == 0: None else: annotation_text_list.append(content) def two_return_to_one_return(content:str): #改行コードを減らす content = content.replace('\n\n','\n') return content path = 'NOT_export/pywrite_test.xhtml' with open(path,'a', encoding='utf-8') as f: #w = 上書き a=追加 f.write('\n') f.write('\t<h1>'+title+'</h1>\n') f.write('\t<h2>現代語訳</h2>\n') f.write('\t<p style="white-space:pre-line">'+two_return_to_one_return(modern_translation)+'\n\t</p>\n') f.write('\t<h2>原文</h2>\n') f.write('\t<p style="white-space:pre-line">'+two_return_to_one_return(original_text)+'\n\t</p>\n') f.write('\t<h2>注釈</h2>\n') for v in range(0,len(annotation_text_list),2): #2づつ f.write(f'\t<h4>{annotation_text_list[v]}・・・{annotation_text_list[v+1]}</h4>\n') # 初期要素の書き込み path = 'NOT_export/pywrite_test.xhtml' with open(path,'w',encoding='utf-8') as f: #w = 上書き a=追加 first_lines = [ '<?xml version="1.0" encoding="UTF-8"?>\n' '<!DOCTYPE html>\n' '<html\n' '\txmlns="http://www.w3.org/1999/xhtml"\n' '\txmlns:epub="http://www.idpf.org/2007/ops"\n' '\txml:lang="ja"\n' '>\n' '\n' '<head>\n' '\t<meta charset="UTF-8"/>\n' '\t<title>徒然草本文</title>\n' '\t<link rel="stylesheet" type="text/css" href="../style/style.css"/>\n' '</head>\n' '\n' '<body>\n' ] f.writelines(first_lines) # 真ん中 get_text_and_write_file("https://tsurezuregusa.com/jyo/") # get_text_and_write_file("https://tsurezuregusa.com/001dan/") # #url作成 for v in range(1,244): time.sleep(1) s = f'https://tsurezuregusa.com/{v:03}dan/' get_text_and_write_file(s) print(s) get_text_and_write_file('https://tsurezuregusa.com/afterword/') path = 'NOT_export/pywrite_test.xhtml' with open(path,'a', encoding='utf-8') as f: #w = 上書き a=追加 # # end f.write('</body>\n') f.write('</html>')
不要な要素を正規表現で削除
ファイルを作成してからvscodeを使い,いらない要素を削除します.
改行を見つける正規表現 pre-line">\n 注釈がない注釈 <h2>注釈</h2>\n(?!\t<h4>) 改行していて,空いているやつ \n\n\t</p>
alt+Enterを押すことで,正規表現でマッチする要素を選択できます(vscode)
css
スマホだと限られたスペースで読みやすく,より多くの情報量を取りたい. そのため,余白が邪魔だったので,cssを書いて余白を詰めている.
html { -webkit-writing-mode: vertical-rl; -webkit-text-orientation: mixed; -epub-writing-mode: vertical-rl; -epub-text-orientation: mixed; writing-mode: vertical-rl; text-orientation: mixed; } .title { font-family: serif; text-align: center; padding-top: 2em; } .author { font-size: 1.5em; font-family: serif; text-align: center; padding-top: 1em; } p { font-size: 1em; font-family: serif; margin: 0px; } h1 { font-size: 1.5em; font-family: serif; margin-right: 1.5em; margin-left: 0.5em; padding: 0px; } h2 { margin: 0px; } h4 { margin-left: 0px; margin-right: 0px; }
完成
読めればいいので,このくらいで完成にする. kindleで徒然草のおもしろい訳を読めるようになったので,私の目的は達成された. この後するのであれば,目次の対応(navigation.xhtml),表紙の対応,配布するなら訳者への許可取りくらいであろうか. 人に見せる品質に到達していないので,私的利用にとどめたい.